

A onda de entusiasmo gerada pelo lançamento do ChatGPT inundou a internet. A possibilidade de um chatbot responder às questões mais banais, tal como aos desafios mais complexos – como escrever poesia, excertos de artigos científicos ou ensaios –, fez com que a Inteligência Artificial e as suas potencialidades voltassem à ordem do dia. Poucos meses depois da celeuma gerada pela afirmação de um engenheiro da Google que dizia detectar consciência num sistema de Inteligência Artificial (IA), uma aplicação de um sistema de IA de grande capacidade à mercê da criatividade dos internautas renovou as narrativas fantasiosas. Quer as positivas, de quem acha que a tecnologia nos vai salvar do que quer que seja, quer as negativas, de quem acha que a tecnologia nos vai condenar ao que quer que seja.
“A onda de entusiasmo abriu mais uma janela de oportunidade para falarmos sobre o estado da arte da Inteligência Artificial e contrariar as narrativas que se criam em seu torno.”
A possibilidade de alunos usarem esta tecnologia em trabalhos capazes de enganar os professores mais atentos, o fim do trabalho dos jornalistas ou o fim do monopólio de pesquisas da Google foram algumas das profecias mais populares e valeram acções concretas como a suspensão do acesso ao ChatGPT em escolas e faculdades. Ao potencial do ChatGPT, que todos pudemos testemunhar, juntou-se a sua rápida ascensão – um milhão de utilizadores em menos de uma semana –, contribuindo para a propagação das crenças mais maximalistas em torno desta tecnologia. E se essas crenças se vão naturalmente esbatendo com o tempo e a investigação, a onda de entusiasmo abriu mais uma janela de oportunidade para falarmos sobre o estado da arte da Inteligência Artificial e contrariar as narrativas que se criam em seu torno. Para começar, importa perceber de onde vem o ChatGPT e quem o criou. Depois, o que torna tão especial e que tipo de relação e influência podemos esperar na sociedade.
O ChatGPT não é obra do acaso, é criação da OpenAI, uma das empresas que na última década tem dado cartas no panorama de desenvolvimento em Inteligência Artificial. Criada em 2015 por Sam Altman, conhecido empreendedor e investidor, e actual líder da empresa; Ilya Sutskever, ex-Google Brain, e responsável pela investigação; Greg Brockman, ex-stripe, e responsável de tecnologia. E financiada por nomes como Elon Musk, também co-fundador que abandonou a empresa em 2018; Peter Thiel, controverso investidor norte-americano conhecido por apoiar Trump, a Amazon Web Services, ou o braço de investigação do YCombinator, uma das mais conceituadas aceleradoras de startups de Silicon Valley. A OpenAI apresentou-se inicialmente como organização sem fins lucrativos, com a missão de abrir a IA, mas quatro anos depois alterou o seu rumo.
O tempo revelou as contingências de empreender um projecto desta magnitude e foi para atrair mais capital que nasceu a OpenAI LP. Isto enquanto os resultados do investimento inicial se traduziam em desenvolvimento, como ferramentas para programadores ou modelos de Inteligência Artificial robustos – nomeadamente o GPT, para geração de texto, lançado 2017 e o DALL-E, para geração de imagens, lançado em 2018. E se nem todos estes resultados chegaram ao grande público e permitiram acompanhar a evolução iterativa do sistema, os lançamentos da OpenAI – ou as dúvidas sobre se modelos deviam ou não ser lançados, como aconteceu com o GPT-2 – foram antecipando de certa forma o debate que agora se ensaia. Depois de algum tempo de vida e dezenas de aplicações dos principais modelos, e da chegada da OpenAI a uma valorização de 20 mil milhões de dólares e a uma receita anual estimada em mil milhões, parece ter sido o ChatGPT a captar toda a atenção, o que não deixa de ser ilustrativo da forma como o desenvolvimento tecnológico e a sua comercialização se relacionam.
Por trás do Chat, o GPT
Com uma interface fácil de utilizar – ao contrário de modelos de Inteligência Artificial em que é preciso saber o mínimo de programação – e um sistema de registo simples e acessível – o que não acontece noutras aplicações do género em que é preciso registar numa fila de espera até ter acesso a um convite –, o ChatGPT não é, em si, uma tecnologia. É uma aplicação do GPT-3.5, optimizada com diálogo humano de forma a gerar respostas aceitáveis para humanos. E, apesar de só esta onda de utilizações inundar as redes sociais, o GPT (nas suas várias versões) já por aí anda há algum tempo e não está sozinho. Tal como acontece com outras tecnologias, a relação dos utilizadores com a Inteligência Artificial é muitas vezes inconsciente ou difusa. Aplicações como o ChatGPT, o Dall-E, Midjourney, ou a própria Lensa, com utilização fácil e resultados cativantes e partilháveis, captam a atenção do grande público, tornando-se símbolos de toda a área. Mas têm um efeito perverso ao ofuscar tudo o que nela se passa, moldando de forma ilusória uma imagem de futuro.
“O ChatGPT não é, em si, uma tecnologia.”
Sem entrar numa contextualização exaustiva, entre os grandes modelos de Inteligência Artificial importa considerar as criações da Google como, entre tantas outras, o LaMDA – no centro da polémica atribuição de consciência — que não é de acesso público, e os já anunciados Gshard e Switch-C, ainda mais poderosos. O RoBERTa criado pelo Facebook, o Megatron-Turing, da Nvidia, e alternativas às grandes criações corporativas, open-source, como o EleutherAI. Ainda assim, por todo o percurso da OpenAI, e a narrativa em que a empresa surgiu, a criação das aplicações citadas e a forma como os modelos de Inteligência Artificial desta empresa têm sido disponibilizados, o ChatGPT é o exemplo perfeito para dissecar. Sem ser o único e grandioso modelo de IA, é um avanço significativo, enquadrado numa estratégia de negócio ultra-lucrativa, com receitas estimadas nos mil milhões de dólares por ano, que nos pode dar pistas para o futuro.
O GPT-3 é um modelo de Inteligência Artificial 10 vezes maior do que o seu antecessor, o que ajuda a explicar o seu sucesso. Saber se o seu sucesso se deve a uma questão de escala, o que significa esta escala e quais as consequências desse incremento, são as grandes questões do momento. Simultaneamente, mergulhar na sua complexidade permite-nos aprender como funciona um modelo de Inteligência Artificial actual, perceber a que se deve tamanho avanço nos tempos que correm, e como é igualmente intrincada a relação entre esta tecnologia e a sociedade.
Cada vez mais esperto, cada vez menos inteligente
O aparecimento da Inteligência Artificial em feeds, torradeiras, máquinas de café, robots e chats tornou o desenvolvimento da área tão fascinante quanto confuso. Da perspectiva do utilizador que simplesmente interage com uma interface, os desenvolvimentos são invisíveis e todos os avanços parecem resultar de um passo de magia ou intervenção divina. Na realidade não é de todo assim. Apesar do uso da IA como buzzword para tudo e mais alguma coisa, vale a pena voltar à ilustração inicial destes modelos apenas como máquinas de computação, mais do que como pequenas réplicas da inteligência humana.
Ao contrário do que pode sugerir a expressão “inteligência”, não existe propriamente uma relação destes modelos com o mundo para além das relações estabelecidas entre os dados fornecidos. Por exemplo: um modelo exposto a um grande conjunto de textos de língua portuguesa pode tornar-se capaz de replicar a forma escrita do português, sem que necessariamente compreenda o tema dos textos, ou sequer tenha de distinguir de que língua se trata. Isto significa que os algoritmos de Inteligência Artificial conseguem discernir e criar relações entre os dados – entre vastíssimas quantidades de dados indiscerníveis ao olho humano – mas não para além destes.
“Apesar do uso da IA como buzzword para tudo e mais alguma coisa, vale a pena voltar à ilustração inicial destes modelos apenas como máquinas de computação, mais do que como pequenas réplicas da inteligência humana.”
No caso dos modelos como o GPT-3 que, como o próprio nome, Generative Pre-Trained Transformer, indica, é um modelo Generativo, esta ideia vai ainda mais longe. O modelo não só tem capacidade de entender relações entre os dados, como gerar novas sequências do mesmo tipo de dados com relações significativas. Mais uma vez, isto não significa que o modelo tenha capacidade de entender as relações de uma perspectiva ontológica, mas que tem capacidade de as detectar e replicar. Um bom exemplo – fora dos modelos generativos – para perceber como genericamente funciona a IA são os modelos de previsão meteorológica, uma das primeiras aplicações para as quais este tipo de ferramenta foi destinada. Para uma previsão meteorológica é necessário processar dados precisos de diferentes fontes e, a partir da sua relação, gerar um resultado com significado. E mesmo sendo a IA uma ferramenta indicada para o fazer, não seria capaz de perceber se está a chover, o significado da chuva de um modo geral; ou a sensação de estar molhado, para além de uma possível descrição do que isso é.
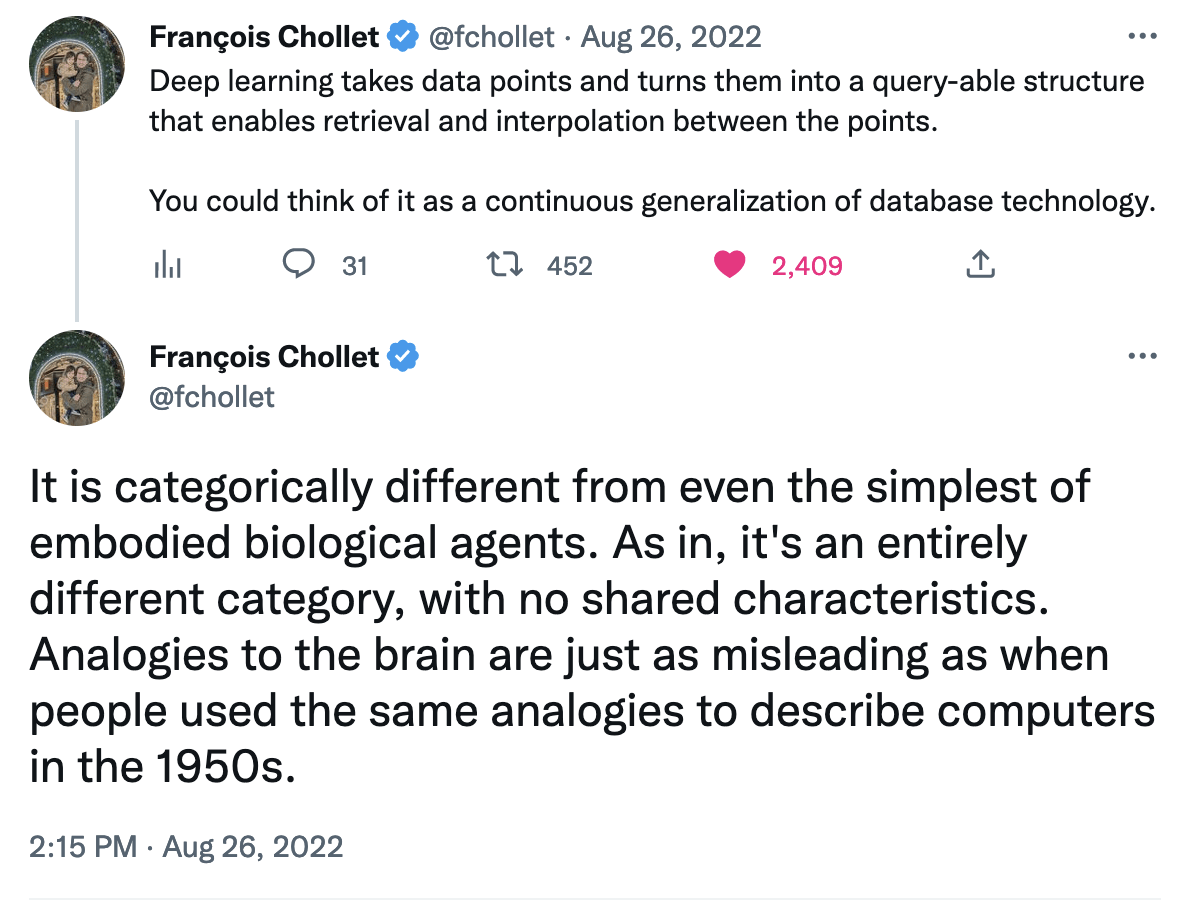
De forma grosseira seria até possível dizer que aquilo que conhecemos por IA é cada vez menos similar à nossa inteligência. O uso do nome explica-se pela forma como nos primórdios de desenvolvimento alguns dos componentes destes sistemas foram modelados à imagem do que se conhecia da biologia, mas erradamente criou-se a ideia de que a IA em poucos anos replicaria o cérebro. Entretanto muito mudou, como recorda François Chollet, um programador importante na área. E embora este ponto possa parecer inútil, é importante estabelecê-lo antes de passarmos à fase seguinte para evitar ilusões. Uma das sensações mais comuns é a de que estamos a assistir a máquinas com uma capacidade evolutiva infinita, e que em pouco tempo adquirirão capacidades iguais às do cérebro humano – algo que se contraria com literacia, o entendimento de modelos como este, e das suas limitações. Se, como François escreveu noutro tweet, alguma ilusão simplista em torno da IA é uma falta de respeito pelo cérebro humano, usemos os nossos.
Generative Pre-Trained Transformer
Tal como anteriormente referimos, o nome do grande modelo de que aqui falamos é auto-explicativo. Se o primeiro termo Generative significa, como visto, que este é um modelo treinado para gerar – no caso, a próxima palavra numa dada sequência – os outros dois conceitos em que assenta, Pre-Trained e Transformer, são duas chaves para compreender o estado da arte da Inteligência Artificial neste domínio.
Um modelo Pre-Trained – ou, em português, pré-treinado – é um modelo de Inteligência Artificial que desenvolveu as suas capacidades através do treino num vasto mas limitado conjunto de dados – esta noção é indispensável à compreensão e crítica da Inteligência Artificial. Dada a complexidade dos modelos de que falamos – e para obter o nível de performance que lhes reconhecemos –, modelos como o GPT-3 necessitam de grandes quantidades de dados para treinar. Neste caso, e dado tratar-se de um modelo generativo de texto, textos em que o modelo pudesse, através das suas operações, inteligir relações com significado.
No caso do GPT-3 sabe-se de onde provêm este dados – embora dada a sua imensidão seja possível discernir ou avaliar a pertinência e correção de cada um. A maioria dos dados para treino do GPT-3, cerca de 66%, provém de uma organização sem fins lucrativos chamada Common Crawl que desde 2018 vasculha a internet recolhendo dados e metadados de páginas aleatórias. Outros advém de processos semelhantes. Como os provenientes da coleção WebText2, que representa 22% dos dados de treino, e tem como critério páginas minimamente populares no Reddit, ou da Wikipedia, representando 3%. Sendo que os restantes cerca de 8% advém de duas bases de dados chamadas Books1 e Books2 com proveniência desconhecida mas com um título suficientemente intuitivo.
“Se para um humano decompomos uma frase como uma sequência de palavras, a máquina não processa a informação do mesmo modo, mas em tokens.”
É exposto a esta imensidão de dados que o modelo descobre relações entre elementos e desenvolve assim as capacidades que lhe permitem emular as capacidades de escrita humana. Mas neste ponto importa considerar que não o faz tal como um humano o faria. Nem processa as informações da mesma forma que nós. Se para um humano decompomos uma frase como uma sequência de palavras, a máquina não processa a informação do mesmo modo, mas em tokens. No caso do GPT é possível experimentar no site da OpenAI como funciona o processo de tokenização mas mais interessante ainda é assimilar conceptualmente esta diferença. É entre estes blocos de significado – geralmente representados por um conjunto de números – que um modelo de IA como este estabelece as relações e não com palavras concretas. Embora essas lhe estejam implícitas ao modelo, veremos mais à frente.

Esta descaracterização das palavras, um processo similar a um etiquetamento, é uma ilustração útil para compreendermos a forma como o modelo aprende a língua: não com foco na dimensão cultural mas com foco em padrões de relações entre blocos, quase como se de um jogo se tratasse. É isto que explica que o modelo seja incapaz de, como no exemplo, entender que uma frase esteja em duas línguas, embora seja capaz de a inteligir e traduzir de forma correta. E as particularidades deste tipo de modelo não se ficam por aqui.
Nesta fase basta lembrarmo-nos da estrutura do ChatGPT para perceber que falta um grau à equação. Os grandes modelos de linguagem, como o que aqui dissecamos, são modelos que desenvolvem capacidades de domínio da língua mas, como é possível prever, não aprendem tudo o que é possível saber nos dados de treino – nem tão pouco têm por defeito a capacidade de ir à Internet procurar (vale a pena ver o PerplexityAI nesse domínio), e isso tem as suas consequências. Por um lado, significa que parte da informação que está contida no modelo está desactualizada – para o ChatGPT, o Cristiano Ronaldo ainda joga no Manchester, e há cerca de um mês ainda jogava na Juventus – e outra pode estar errada – como mostra esta receita de bacalhau à Brás.

A questão da incorreção da informação é particularmente interessante e desafiante. Os modelos de Inteligência Artificial têm formas de validar a informação de que dispõem, contudo nem sempre o fazem. Por exemplo, se depois de dada a receita de Bacalhau à Brás perguntarmos ao modelo se tem a certeza da receita que acabou de dar, este sugere que provavelmente está errada; contudo, nada dessa incerteza foi expressa na resposta anterior.
Por último, a subjectividade das palavras e os significados culturais que elas podem conter é também uma dimensão desafiante. Sendo treinado num conjunto vasto de dados que não são humanamente selecionados é expectável que o modelo replique padrões de comportamento com viés. E se exemplos que expressem racismo, xenofobia ou alguma forma de discriminação não têm faltado nos últimos tempos, alguns dos quais entretanto resolvidos com mais treino, outros surgirão à medida que os usos forem sendo testados ou poderão até nunca ser descobertos – essa é, aliás, uma das grandes críticas aos modelos deste género, como veremos mais à frente.
Mesmo depois de expostas as debilidades, é impossível negar a capacidade que o modelo tem para cumprir tarefas de natureza textual, que surpreendeu toda a gente. Apesar de ter sido concebido para prover palavras em sequência – gerar texto – o modelo revelou-se extremamente capaz noutras tarefas como tradução, escrita de código, sintetização de texto, etc. E é sobre essa capacidade que assentam tanto expectativas como questões. Sendo, como vimos, dez vezes maior do que o seu concorrente seguinte, o GPT tem cerca de 175 mil milhões de parâmetros que correspondem a cerca de 800 GB. Um valor que resulta da enormidade de dados em que foi treinado e da estrutura interna como foi desenhado – número de camadas de redes neuronais, formas como estas camadas se relacionam, etc –, aquilo a que vulgarmente se chama a sua arquitectura, e da grande capacidade computacional empregue para conjugar tudo isto. Mas os pontos de interesse não se ficam por aí. É aqui que entram os Transformers.
“Mesmo depois de expostas as debilidades, é impossível negar a capacidade que o modelo tem para cumprir tarefas de natureza textual, que surpreendeu toda a gente.”
Attention is All You Need
Com nome de personagem robótica de uma série de filmes de animação de ficção científica que bem pode contribuir para a imaginação da IA como algo digno de super-heróis, os Transformers são neste contexto algo bastante diferente. E bastante relevante. Apresentado pela primeira em 2017 num artigo científico publicado por um grupo de investigadores com ligação à Google com o título “Attention is All You Need”, o termo Transformer designa uma arquitectura de modelos de Inteligência Artificial revolucionária na área – e aplicada noutros modelos como os acimas citados BERT (Bidirectional Encoder Representations from Transformers) ou o RoBERTa. Para percebermos concretamente o que representa esta inovação, voltemos aos exemplos e às simplificações.
“A nossa capacidade (de processamento e cultural) faz com que tenhamos a habilidade de olhar para os inputs como um todo, criando uma ideia geral; já para as máquinas não é bem assim.”
Como vimos, os modelos de computação não entendem as palavras nem as frases como os humanos. Para entendermos o sentido de uma frase não passamos por um processo de tokenização, nem para entendermos uma imagem a temos de analisar parcela a parcela. A nossa capacidade (de processamento e cultural) faz com que tenhamos a habilidade de olhar para os inputs como um todo, criando uma ideia geral; já para as máquinas não é bem assim. Sem essa capacidade de encontrar significado através da abstração, os processadores precisam de decompor os inputs em unidades que tenham para si, computador, algum significado a partir do qual possam criar relações. A forma como estes inputs se transformam em outputs, – o que seria para os humanos o processo de cognição – é determinante para os resultados que se obtêm, e é determinado pela forma como cada modelo de Inteligência Artificial é estruturado. E aqui chegamos às redes neuronais.
A arquitectura dos modelos de Inteligência Artificial representa a forma como o modelo interpreta a informação, neste caso de uma dada sequência. Se nós humanos criamos a tal abstração, a forma como modelos como este processam informação – através das chamadas redes neuronais – é inspirada nesse processo, numa relação com particularidades e limitações óbvias. As redes neuronais enquanto conceito foram introduzidas na área da IA há muito. A forma como são aplicadas depende do estado da arte da investigação tanto como do desenvolvimento tecnológico – e a sua semelhança com a forma como funciona a inteligência humana é tão difícil de comprovar como é difícil definir o que é inteligência.
Antes do surgimento da Transformer, as arquiteturas mais comuns de redes neuronais para processamento e geração de texto, baseavam-se em princípios datados dos anos 80 – com melhorias ao longo dos anos. As CNN (Convolutional neural network) inspiradas no conceito neocognitron de Kunihiko Fukushima em 1980, e as RNN (Recurrent Neural Networks) inspiradas no trabalho de David Rumelhart. Quando aplicadas neste tipo de tarefas, estas arquiteturas são comumente configuradas para processar os dados de uma forma sequencial, um método conhecido por Seq2seq. Nesta configuração, cada token é processado de uma forma linear, relacionando-se apenas com o anterior (como se lêssemos palavra a palavra relacionando a palavra seguinte apenas com a anterior), e as limitações desta formulação foram-se tornando evidentes.
Por processar de forma linear os dados e estabelecer apenas relações curtas, os modelos desta natureza, quando expostos a grandes sequências, acabavam por esquecer parte da informação (como se chegassem ao fim de um texto sem se lembrar do princípio) e por, ao longo de grandes processos de treino, deixar de conseguir estabelecer novas relações entre os tokens (como se fosse um aluno a tentar aprender matemática que se ia esquecendo das aulas iniciais e por isso tornando mais difícil perceber cada lição). Estes problemas foram motor de uma série de investigações e avanços na área. Entre estes, a criação da arquitectura LSTM, por Jürgen Schmidhuber, desenvolvido ao longo dos anos 90, ou dos Fast Weight Networks, uma das primeiras tentativas do alemão para resolver o segundo problema mencionado, que acabou por não se tornar tão popular.
“Por muito que dentro do modelo de linguagem haja um ideia sobre o que é um ‘elefante’, seria impossível ao GPT identificar visualmente um elefante, ou reconhecer o som de um, uma vez que se trata de um modelo de linguagem.”
Nos modelos de arquitetura LSTM o modelo contornava a perda da informação fazendo com que parte da sequência fosse propositadamente esquecida ou ignorada, criando espaço para a retenção do mais relevante. Mas em todo o caso continuavam a existir ineficiências. Dada a antiguidade dos modelos, e salvo todas as actualizações, os processos em que decorriam faziam pouco uso da capacidade de computação actual por realizarem poucas operações em paralelo. Assim, a arquitectura Transformer surgiu como um avanço significativo nestas questões e com algumas ideias novas.
São três as grandes ideias que convergem nesta arquitectura e que vale a pena reter. Por um lado, e como sugere o nome do capítulo, esta arquitectura introduz uma forma diferente de processar a atenção, com um mecanismo de self-attention (auto-atenção) e de cross-atention (atenção cruzada). A self-attention faz com que o modelo tenha capacidade de num dado input perceber que partes deve ou não reter (como acontece por exemplo na pesquisa do Google que ignora algumas palavras), já a cross-atention é semelhante, mas sobre o output. Para além disto, a arquitectura Transformer pressupõe também a projecção dos inputs para um espaço comum (a forma mais fácil de entender é imaginar que o modelo traduz todos os inputs para uma espécie de língua própria, sendo que essa língua é a matemática), o que faz com que se torne capaz de lidar com diferentes tipos de dados. E, por último, representa também um grande avanço no que toca à computação paralela, o que significa que promove o processamento de dados em paralelo, ao contrário dos exemplos sequenciais que vimos anteriormente.
A projecção dos dados para um espaço comum de que falámos ainda agora faz com que o modelo de IA crie aquilo a que se chama ‘representações’. Transportando para uma linguagem humana, essas representações são como conceitos, e é essa representação (na tal linguagem própria, matemática) que permite a transferência de significado de uma forma mais célere, por exemplo entre línguas. Dada uma determinada frase numa língua, o modelo não precisa de traduzir palavra por palavra de forma sequencial, traduzindo a partir deste representação interna que é capaz de gerar. Importa relembrar que esta representação não é ontológica – em todas as suas dimensões -, mas sim matemática, sendo representada por um vector e que não resulta propriamente de um processo de compreensão, mas de reconhecimento de padrões nos dados. Isto é: por muito que dentro do modelo de linguagem haja um ideia sobre o que é um ‘elefante’, seria impossível ao GPT identificar visualmente um elefante, ou reconhecer o som de um, uma vez que se trata de um modelo de linguagem. Um ponto que nos recorda que estes modelos são isso mesmo: modelos, sem a dimensão corpórea e sensorial vulgarmente indissociável da inteligência, e serve de porta de entrada ao universo de críticas e considerações importantes que se fazem sobre este modelo e outros do género. Da mesma forma que nos deve deixar alerta para a forma como estas representações podem ser enviesadas ou pouco rigorosas.
Modelos de Inteligência Artificial Negócio
Feita a explicação técnica, que nos ajuda a perceber porque o ChatGPT não é o Santo Graal da Inteligência Artificial, algumas questões continuam por responder. É que as potencialidades destes modelos não dependem só das possibilidades tecnológicas que são exploradas, mas de quem os controla, como e quais os seus modelos de negócio. E em última análise deveriam depender também de um processo de escrutínio democrático.
O lançamento do ChatGPT pode explicar-se como a criação de um sub-produto tanto como uma campanha de publicidade junto do grande público. Com a criação de uma aplicação gratuita de fácil utilização por qualquer utilizador a OpenAI conseguiu captar a atenção de tudo e de todos, e pôr muita gente a falar da sua criação que desde 2020 está disponível, o que só adensou a confusão sobre esta área, omitindo as somas que estão por de trás destas criações aparentemente simples e gratuitas.
“O lançamento do ChatGPT pode explicar-se como a criação de um sub-produto tanto como uma campanha de publicidade junto do grande público.”
Apesar de não haver dados concretos e da parceria com a Microsoft, que faz com que o ChatGPT corra na infraestrutura da Microsoft Azure, Sam Altman, um dos responsáveis da OpenAI, twittou por altura em que a aplicação chegou ao milhão de utilizadores que os custos operacionais eram “eye watering” (de ficar com lágrimas nos olhos, em português). Para além do custo de desenvolvimento da tecnologia, existe o custo de a manter activa, que segundo cálculos de um professor associado da Universidade Maryland podem ser cerca de três milhões de dólares por mês. E se, feita a primeira parte da explicação, isso pode parecer um desperdício (o modelo já existia, estava operacional e no activo), a forma como o seu surgimento sequestrou a atenção do público, que lhe valeu títulos dos media e a tornou protagonista das narrativas sobre IA, pode bem ter valido a pena – nomeadamente no que toca à obtenção de capital através de novos investimentos. Notícias recentes dão conta da vontade da Microsoft de adquirir 49% da OpenAI por um valor a rondar os 15 mil milhões de dólares.
Apesar de ser pouco explícito, nem o ChatGPT é gratuito. Em vez disso, é parte de um plano de demo, que dá acesso ao utilizador ao equivalente a 18$ de créditos ou 3 meses de utilização, o que em usos criativos pode parecer muito, mas em usos críticos rapidamente se pode esgotar. Estes custos prendem-se não só com o desenvolvimento da tecnologia em si, e treino do modelo, como com a necessidade de infraestruturas para fazer correr essa tecnologia. E apesar de haver alternativas em desenvolvimento de natureza open source e licenças abertas, o ímpeto criado pelo marketing da OpenAI e a assistência oferecida por uma empresa com fins lucrativos, dificilmente é replicada de forma comunitária – como vemos noutras áreas como o design, o software educativo ou até mesmo os sistemas operativos – o que pode trazer consequências.
“Apesar de ser pouco explícito, nem o ChatGPT é gratuito.”
Neste capítulo vale a pena voltar a situar os modelos entre os seus competidores e perceber que, muito provavelmente, a Google não lança uma aplicação semelhante ao ChatGPT por não se enquadrar no seu modelo de negócio mais do que por não dispôr das capacidades tecnológicas de o fazer. Recordemos que os autores do artigo sobre os Transformers faziam parte da empresa – e pensemos que provavelmente as nossas pesquisas já são processadas por modelos semelhantes. Contudo, é importante para o modelo da Google que passemos pela página com todos os resultados onde introduzem a publicidade que rentabiliza o negócio. Já para a OpenAI, cujo negócio é o próprio acesso aos modelos de computação, nada interessa mais do que uma certa ideia de insuperabilidade e de que está no limiar da revolução. Algo que se tem visto nas notícias e nas redes sociais, onde até já se antecipa o GPT-4 planeado para o final do ano. Sem que ainda se tenha dado propriamente espaço a um debate democrático sobre este tipo de modelos, o seu desenvolvimento avança, sobretudo na esfera corporativa, enquanto a regulação se decide em gabinetes de políticos e à distância da complexidade que nos afasta de um entendimento crítico.
Do you know em que língua está this sentence?
Existem várias dimensões de críticas associadas ao ChatGPT e aos modelos desta natureza, e a sua fundamentação é bastante diversa e relevante. Se umas se focam naquilo que modelos como este ainda são incapazes de fazer, ou naquilo para que podem ser usados hoje em dia, outras são mais abrangentes e relacionam-se directamente com a forma como estes modelos chegam a existir, e nos relacionamos com eles. Comecemos pelas primeiras.
“Existem várias dimensões de críticas associadas ao ChatGPT e aos modelos desta natureza, e a sua fundamentação é bastante diversa e relevante.”
Apesar do ChatGPT dar respostas que podem ser impressionantes, é preciso não esquecer o verdadeiro significado desse verbo e indagar mais a função nas suas capacidades. Tendo capacidade para gerar texto com grande rapidez e aparente correção, que se transformou em milhares de exemplos que inundaram as redes sociais e povoaram a imaginação, o ChatGPT tem sérias limitações na performance de testes de lógica básicos. O exemplo da frase que surge no título deste capítulo é apenas um deles. Mas muitos outros têm sido amplamente documentados – e alguns destes são particularmente ilustrativos. A incapacidade de contar do ChatGPT é dos que nesta categoria salta à vista – dadas instruções ao bot que contemplem operações numéricas, mesmo que muitos simples, é visível a sua incapacidade de resolver estas operações. Também perante frases com alguma ambiguidade que seria facilmente resolvida pelo senso comum, o ChatGPT revela lacunas. E se essas limitações desaparecem, não é porque a máquina aprenda sozinha, mas porque este demo servem também para testar e optimizar resultados – que podem ser corrigidos depois de ser sinalizados através da plataforma que convida o utilizador a avaliar os resultados gerados, ajudando a melhorar o modelo da empresa ou depois se tornarem virais. É que alguns dos problemas detectados, não são só defeitos, são próprios do seu feitio.
A forma como os modelos funcionam, criando relações invisíveis ao olho humano a partir de grandes quantidades de dados não filtrados faz com que o modelo tenha por defeito potencial de replicar padrões nocivos e enviesados. E se alguns exemplos podem ser bastante óbvios, sendo facilmente evitados até antes do modelo ser disponibilizado, outros são encarados como um dano colateral imprevisível pelo qual muitas vezes as empresas não assumem propriamente responsabilidade, como bem aponta a linguista Emily Bender citando Deb Raji, investigador Aem IA da Mozilla, numa crítica ao artigo do Washington Post sobre o ChatGPT. A mesma crítica onde se pode ler uma referência a uma das reações públicas de Sam Altman quando confrontado com um exemplo em que o ChatGPT gerou um output claramente racista, e CEO da empresa sugeriu ao utilizador que “fosse ajudar a empresa a melhorar”.
“A ideia de que a evolução da Inteligência Artificial passa apenas por este modelo e que é para ele que todos devem colaborar é errada – até pela forma como o termo ‘inteligência’ mantém sempre aberta a definição.”
Este ponto é interessante e traz-nos de volta para a forma como o desenvolvimento de Inteligência Artificial se relaciona com a sociedade e como, neste caso em particular, se criaram narrativas maximalistas direcionadas a um só modelo entre tantos. A ideia de que a evolução da Inteligência Artificial passa apenas por este modelo e que é para ele que todos devem colaborar é errada – até pela forma como o termo “inteligência” mantém sempre aberta a definição. Na verdade, até a forma como estes modelos são atualmente concebidos é alvo de uma interessante contestação a vários níveis.
No artigo On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?, Emily Bender e Timnit Gebru, duas das mais escutadas e interessantes vozes que ecoam perspectivas críticas, alertam para as consequências da prossecução destes modelos. Para além da possibilidade de estereotipação, discriminação, ou informação incorrecta com consequências potencialmente perigosas – que não são de desvalorizar se pensarmos em usos críticos destes modelos –, as autoras alertam que, a dimensão e arquitectura de modelos como este dependem de mais recursos (quer dados, quer computacionais) que implicam mais custos o que pode a acentuar desigualdades no acesso a tecnologia estado-de-arte. Nesse sentido, sugerem como potencial caminho para mitigação dos problemas uma abordagem diferente ao desenvolvimento, com menos foco em intensa computação e mais em trabalho humano na seleção e curadoria de conteúdo para treino. Uma ideia que se ilustra de forma interessante com o trabalho de Kathy Crawford, Anatomia de uma IA, ou a perspectiva da IA feminista de Caroline Sinder – e uma provocação apelando a uma maior valorização ao trabalho humano na base dos modelos de IA.
“O GPT não é o único modelo relevante de IA, a sua arquitectura é inovadora mas não é uma bala de prata, e, em cima de tudo isso, é propriedade de uma empresa com fins lucrativos.”
Estas ideias reforçam a tónica sobre o facto destes modelos serem matemáticos (baseados em probabilidades), detectando e replicando padrões e estruturas que reconhecem nos dados aleatórios, muito mais do que compreendendo na realidade e em todas as dimensões o que leem ou escrevem. Lembram-nos que os modelos geram o texto mais provável e não o texto mais correcto – até porque não têm necessariamente uma definição do que é correcto. E ao mesmo tempo ajudam-nos a expandir a perspectiva sobre o modelo, traduzindo na prática aquilo que aos poucos vamos dizendo: que o GPT não é o único modelo relevante de IA, que a sua arquitectura é inovadora mas não é uma bala de prata e, em cima de tudo isso, que é propriedade de uma empresa com fins lucrativos — algo para que já devíamos estar avisados depois da bolha dot com ou dos amplos debates sobre redes sociais para os quais acordámos socialmente demasiado tarde, quando já todos estávamos nas mãos do Facebook.
Momento Eliza
De uma forma geral, a sensação é a de que estamos a viver mais um momento eufórico do ciclo de entusiasmo em torno da IA, com todas as consequências que essa euforia traz, como usos irresponsáveis e efabulação das capacidades computacionais. Nos primeiros meses de disponibilização do ChatGPT, um conhecido fórum sobre desenvolvimento baniu todas as respostas geradas pelo modelo por conter demasiados erros de código que se fossem implementados podiam trazer consequências. Recentemente, soube-se que a aplicação para acompanhamento de saúde mental, Koko, testou uma funcionalidade em que as respostas geradas para os seus utilizadores eram criada pelo GPT-3 com supervisão de um humano, que podia validar ou rejeitar a sugestão do modelo, e partilhou a experiência no Twitter. Segundo a sua análise a taxa de aceitação das respostas foi alta mas só enquanto os utilizadores não eram informados de que estavam a interagir com a intermediação do modelo. Tal utilização podia ser mais apropriada para recuar na cronologia da IA e recordar um modelo – muitíssimo mais rudimentar – que ficara para a história.
“Nem os avisos do seu criador de que não era de qualquer modo inteligente, impediram que algumas pessoas se convencessem de que a máquina tinha sensações humanas.”
Eliza foi um modelo criado em 1964 por Joseph Weizenbaum para emular um psiquiatra, gerando respostas aparentemente coerentes, perguntando ao utilizador a partilhar mais da sua história. E nem os avisos do seu criador de que não era de qualquer modo inteligente, impediram que algumas pessoas se convencessem de que a máquina tinha sensações humanas. A esta tendência para ilusoriamente atribuirmos características e capacidades humanas a máquinas e objetos ficaria conhecida como Efeito Eliza. Mas, mais uma vez, nem por isso a sua documentação impede outro momento Eliza. Desta vez, o público é mais alargado e as consequências só o futuro dirá.
O debate sobre a Inteligência Artificial já é longo mas ainda agora começou e a participação de todos é indispensável para que se possa tirar partido de tal tecnologia de uma forma informada, democrática e benéfica para todos. Mas a participação de cada um deve ser mais do que lançando profecias avulso sobre um futuro hipotético, geralmente baseadas em entendimentos superficiais da tecnologia. Embora seja possível imaginar centenas de usos de modelos como este, não é de todo provável que assumam lugares de destaque na sociedade e, sobretudo, não é de todo desejável. Imaginar uma sociedade que delegasse tarefas críticas a um modelo corporativo, treinado em dados desconhecidos, e não selecionados, é mais assustador do que a possibilidade de perder o emprego em si. De resto, a nossa dependências das redes sociais corporativas, a forma como os seus algoritmos enviesados geraram questões complexas ou as suas decisões se revelaram pouco democráticas devia servir ponderação antes de pormos outra empresa tecnológica, ou a própria tecnologia, num pedestal.
“Imaginar uma sociedade que delegasse tarefas críticas a um modelo corporativo, treinado em dados desconhecidos, e não selecionados, é mais assustador do que a possibilidade de perder o emprego em si.”
Como li num comentário irónico no YouTube, se para o ChatGPT gerar respostas outputs corretos, os inputs têm que ser precisos, então os designers e redatores podem ficar descansados porque os clientes não sabem fazer. Uma piada inofensiva capta algumas das críticas e pode mitigar algumas das narrativas mais descoladas da realidade. Ao projetarmos usos altamente revolucionários do ChatGPT – quer seja a substituição de uma profissão ou o fim da arte – não estamos só a sobrevalorizar a capacidade do meu modelo e a desvalorizar a capacidade humana capaz para levar a cabo tal tarefa. Estamos desde logo, num processo mais profundo, a descartar tudo o que não é textual ou traduzível para texto da nossa imaginação social. E esse tudo, embora seja invisível, é muitíssimo.
Antes de me dedicar à escrita deste texto para ter um exemplo concreto para esta comparação, resolvi correr no ChatGPT o mesmo prompt que surgia na minha cabeça. Depois de toda esta viagem, rever os resultados não deixa dúvidas sobre as diferenças. Embora o modelo escreva com correção e fluidez, a resposta é notavelmente superficial e simplista, omitindo informações muito importantes como a propriedade do modelo, as principais críticas, ou sequer o esboço de uma tentativa de explicação sobre como este funciona. Acreditar nos seus outputs como algo realmente inteligente passível de tornar obsoletos revela mais sobre uma visão reducionista do que é a humanidade e a inteligência do que propriamente uma visão ponderada do futuro. Com certeza que os próximos anos serão marcados por uma popularidade ainda maior da Inteligência Artificial e a sua aplicação em todos os pontos em que possa gerar lucro para as grandes empresas, mas se o lucro não é a única meta da nossa vida – e queremos encarar a crise social e ambiental em que vivemos, lidando com problemas com desinformação e os altos gastos energéticos –, é bom que comecemos a escrever novas narrativas e, para que tenham alguma imaginação, rigor e relevância ecológica, é bom que mantenhamos a IA no seu devido lugar.
O que diz o ChatGPT?
(Este texto foi gerado pelo ChatGPT.)
O ChatGPT é um modelo de linguagem criado pela OpenAI que permite que usuários tenham conversas com ele. Ele foi treinado com milhões de exemplos de conversas humanas e é capaz de responder de forma razoavelmente fluente em uma variedade de tópicos. Embora seja um avanço impressionante em termos de tecnologia de linguagem, existem algumas críticas importantes que o público deve ter em consideração ao usar o ChatGPT.
Uma das principais críticas é que o ChatGPT não é capaz de compreender o contexto das conversas de forma tão profunda quanto um ser humano. Ele pode responder de forma razoável às perguntas que lhe são feitas, mas muitas vezes suas respostas são genéricas ou pouco relevantes para o tópico em questão. Isso pode tornar as conversas com o ChatGPT menos interessantes ou menos engajantes do que as conversas que as pessoas têm entre si.
Outra crítica é que o ChatGPT foi treinado com exemplos de conversas humanas, mas isso não significa que ele é capaz de replicar a forma como as pessoas realmente se comunicam. Ele pode reproduzir a forma como as palavras são usadas em diferentes contextos, mas não pode captar a subtileza e a complexidade das relações humanas de forma precisa. Isso pode levar a conversas estranhas ou pouco naturais com o ChatGPT, que podem ser desconcertantes para os usuários.
Além disso, o ChatGPT foi treinado em inglês, o que significa que pode ter dificuldade em compreender ou responder corretamente a perguntas feitas em outros idiomas. Isso pode limitar o seu uso para pessoas que falam apenas inglês ou que estão dispostas a se comunicar apenas em inglês.
Por fim, é importante lembrar que o ChatGPT é apenas um modelo de linguagem criado por computador, e não é capaz de replicar a inteligência humana de forma precisa. Ele pode ser divertido de se usar em certas situações, mas não deve ser confundido com um ser humano real ou usado como substituto de interações humanas reais.
Em resumo, o ChatGPT é uma ferramenta impressionante de linguagem que pode ser divertida de se usar em certas situações. No entanto, é importante levar em consideração as suas limitações e entender que ele não é capaz de replicar a inteligência.
O autor agradece a Miguel Freire e José G. de Almeida por comentários e correcções durante a produção deste artigo.
Actualizado dia 11/04 para clarificação da ideia de significado associada à IA na frase




You must be logged in to post a comment.